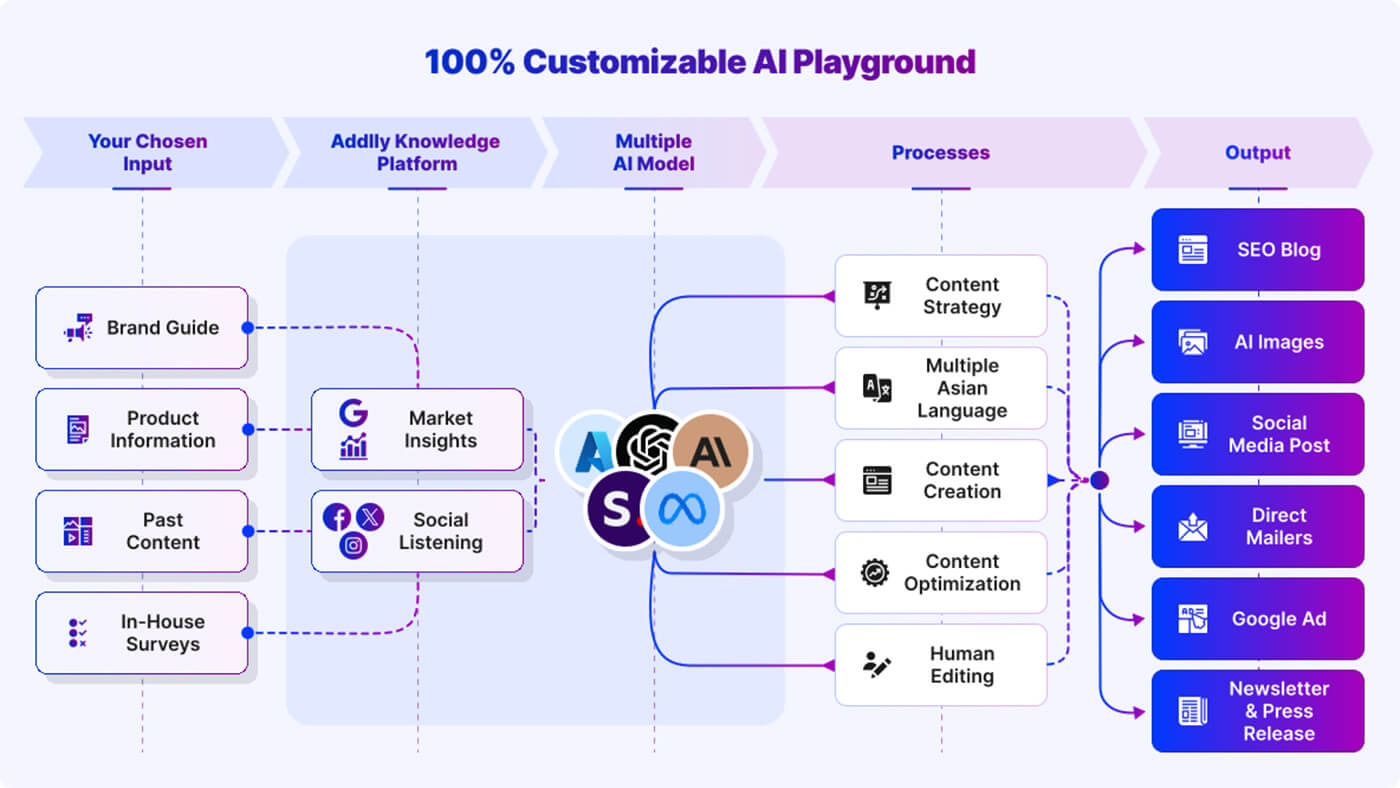
How Does Multi-LLM Orchestration Work in Addlly AI?
Multi-LLM orchestration is the system-level approach to coordinating multiple large language models so they operate as a structured workflow rather than isolated generators. As AI systems increasingly influence how content is discovered, summarised, and cited, single-model workflows often struggle to deliver the clarity, consistency, and interpretability required for reliable AI visibility.
In Addlly AI, multi-LLM orchestration functions as infrastructure for AI search visibility and Generative Engine Optimization (GEO). This page explains how orchestration works in practice within Addlly AI, why it improves GEO outcomes, and how it enables scalable, reliable content systems designed for both human readers and AI engines.
What Is Multi-LLM Orchestration?
Multi-LLM orchestration is the system-level process of coordinating multiple large language models so they operate as a structured workflow rather than relying on a single AI model to handle every task.
In Addlly AI, multi-LLM orchestration is designed specifically for marketing, content, SEO, and AI search visibility workflows, where accuracy, consistency, and interpretability matter more than raw text generation.
Instead of asking one model to think, decide, write, evaluate, and validate all at once, orchestration breaks work into distinct tasks and assigns each task to the most suitable model.
Why Addlly AI Uses Multiple LLMs Instead of One
Most AI tools rely on a single large language model and attempt to solve complexity through increasingly detailed prompts. This works for isolated tasks, but it breaks down in production environments where content must be accurate, repeatable, and interpretable by both humans and AI systems.
A single-model dependency creates three structural problems.
| Constraint | What Happens in Practice |
|---|---|
| Cognitive overload | One model is forced to reason, generate, evaluate, and correct its own output, increasing error risk |
| Inconsistent behaviour | Outputs vary in tone, structure, and terminology across similar tasks |
| Poor scalability | Quality degrades as volume, formats, and use cases increase |
There is also an underlying risk and bias issue. When one model becomes the sole decision-maker, its blind spots, training biases, and reasoning shortcuts directly shape every output, with no system-level correction.
Multi-LLM orchestration addresses this by separating responsibilities instead of amplifying prompts.
Rather than expecting one model to do everything well, tasks are decomposed. Interpretation, analysis, generation, and validation are handled independently, allowing each step to be optimized and checked.
The result is not “smarter” content in the creative sense. It is more predictable, more auditable, and more stable content.
This matters because modern visibility depends less on originality and more on clarity. AI-driven search, summaries, and citations reward content that is structurally legible and consistently framed. Systems built on a single model struggle to deliver that reliability over time.
Multi-LLM architecture is therefore not a performance upgrade. It is a risk-management decision.
Core Principles Behind Multi-LLM Orchestration
Multi-LLM orchestration is not about stacking models for power. It is about designing constraints, responsibility, and control into AI-driven workflows. The system works because it follows a small set of non-negotiable principles.
1. Reliability over novelty
Newer or larger models are not automatically better for every task. Stability, predictable behaviour, and consistent outputs matter more than creative variance, especially in SEO, GEO, and brand-critical content.
2. Clear separation of responsibilities
Each model is assigned a narrow, well-defined role. Reasoning is separated from generation. Evaluation is separated from creation. This reduces error compounding and prevents models from “grading their own work.” Models such as ChatGPT, Claude, Gemini, Perplexity, and Grok are assigned to narrowly defined roles based on their strengths, ensuring reasoning, generation, and validation are handled by the most suitable system component.
3. Deterministic outputs where it matters
Not every task benefits from open-ended creativity. Rules and checks govern structural decisions, entity usage, formatting, and visibility signals so outputs remain repeatable across scale.
4. Redundancy for high-risk decisions
Critical steps do not rely on a single model’s judgment. Validation layers exist to catch ambiguity, inconsistency, or misalignment before outputs are finalised.
5. Systems before prompts
Prompts are treated as inputs, not control mechanisms. The orchestration logic determines flow, sequence, and constraints. This prevents prompt inflation and keeps workflows manageable as complexity grows.
Together, these principles ensure that AI behaves less like an unpredictable assistant and more like infrastructure. The focus shifts from “what the model can do” to “what the system guarantees.”
How Orchestration Works Inside Addlly AI (High-Level Flow)
Multi-LLM orchestration inside Addlly AI follows a controlled, stage-based flow. Each stage exists to remove ambiguity, reduce risk, and ensure outputs remain consistent as content moves from strategy to execution.
Input Interpretation
Every workflow begins by clarifying intent before any content is created.
- Interprets the goal of the request, not just the prompt text
- Identifies content type, channel, and visibility requirements
- Defines constraints that guide downstream execution
Task Routing
Once intent is clear, work is decomposed and assigned deliberately.
- Separates analytical, structural, and generative tasks
- Routes tasks based on functional suitability, not model size
- Prevents one model from owning the entire decision chain
Model Execution
Models operate as specialised components within defined boundaries.
- Each model receives only the context required for its task
- Output formats and expectations are constrained
- Execution focuses on consistency over improvisation
Cross-Checking and Validation
Outputs are reviewed before being accepted into the final system state.
- Verifies structure, clarity, and formatting
- Checks entity usage and terminology consistency
- Reduces hallucination and interpretation drift
Final Output Assembly
Validated outputs are combined into a cohesive result.
- Maintains alignment across formats and channels
- Balances human readability with AI interpretability
- Produces predictable, repeatable outcomes
When validation requires external grounding or broader contextual awareness, the orchestration layer may incorporate models such as Perplexity or Grok alongside ChatGPT, Claude, and Gemini. This allows outputs to be checked not only for structural and semantic accuracy, but also for contextual relevance and information reliability.
Task-Based Model Routing in Addlly AI
Task-based routing ensures that intelligence is applied where it fits best, rather than relying on a single general-purpose model to do everything.
When Different Models Are Selected
Models are chosen based on the nature of the task, not on general capability. In practice, different stages within a workflow may route tasks to models such as GPT, Claude, Perplexity, Grok, or Gemini based on functional requirements rather than vendor preference.
For example, some tasks prioritise reasoning stability, others benefit from controlled generation, and others require precise validation. The orchestration layer abstracts these differences, ensuring consistent outcomes even as underlying models evolve
- Interpretation and analysis require reasoning stability
- Generation requires controlled creativity
- Validation requires precision and constraint awareness
Matching Models To Task Types
Each task type benefits from a distinct reasoning profile aligned to its role in the workflow. By matching tasks to models suited for that function, the system avoids overloading any single model with competing responsibilities and maintains consistency across outputs.
- Analytical stages prioritise consistency and structure
- Generative stages prioritise clarity within defined limits
- Review stages prioritise accuracy and alignment
Where Multi-LLM Orchestration Shows Up Across Addlly AI’s AI Agents
Multi-LLM orchestration is not a separate layer that users interact with directly. It operates inside agents, shaping how analysis, generation, and validation happen across different workflows. Each agent applies the same orchestration logic, but in ways that reflect its specific purpose.

This agent relies heavily on interpretation and validation before generation ever occurs.
- Interprets how AI systems currently read brand content and entities
- Separates diagnostic analysis from explanatory output
- Cross-checks findings to reduce misclassification and noise

Here, orchestration balances strategy with execution.
- Translates visibility goals into structured content requirements
- Separates intent mapping from content structuring
- Validates outputs for AI interpretability before delivery

Search workflows demand consistency more than creativity.
- Routes keyword and intent analysis separately from writing
- Applies structural checks before optimisation suggestions
- Prevents over-optimisation caused by generative bias
- Interprets topic intent and search context independently
- Separates outlining, drafting, and refinement
- Validates structure, entities, and clarity before final output
Short-form content still requires system discipline.
- Distinguishes message framing from copy generation
- Maintains brand voice consistency across posts
- Prevents variation drift across platforms and formats

Newsletters require coherence across sections, not just good writing.
- Routes audience intent analysis separately from content creation
- Validates flow, hierarchy, and messaging consistency
- Ensures outputs remain scannable and summarisation-friendly
Across all agents, the same principle applies: models do not decide the workflow. The system does.
This is what allows different agents to behave consistently while handling very different tasks, from audits to content production to visibility optimisation.
How Consistency Is Maintained Across Multiple Models
Multi-LLM systems fail when consistency is treated as an output problem. In reality, consistency is an input and process problem. If models are allowed to interpret brand voice, entities, and structure independently, variation becomes inevitable.
Inside Addlly AI, consistency is enforced before and during generation, not after.
Rather than asking models to “sound consistent,” the system defines what cannot change, regardless of which model is used.
Brand Voice Is Locked At The System Level
Brand voice is not inferred from examples each time content is generated. It is treated as a fixed operating constraint.
This means tone, narrative posture, and writing boundaries are applied upstream, shaping how models reason and respond rather than asking them to self-regulate. Creativity exists, but only inside a defined envelope.
This approach prevents stylistic drift as volume increases and as different agents handle different formats.
Entities Are Treated As Infrastructure, Not Keywords
In orchestrated workflows, entities are not decorative. They are structural. Core brand entities, product terms, categories, and contextual references are standardised across workflows. Models do not “decide” naming conventions or reinterpret terminology.
They operate against a shared entity layer that reinforces clarity for both search engines and AI systems. This is critical for AI visibility, GEO alignment, and citation reliability, where inconsistent entity usage directly reduces discoverability.
Structure Carries Meaning, Not Just Format
Consistency is also structural. Headings, hierarchy, section logic, and information flow are validated as part of the workflow. This ensures content remains legible to AI systems that summarise, compress, or surface answers based on structure rather than prose quality.
The system checks whether content can be understood without interpretation. If meaning depends on inference, it is corrected.
Why This Works Across Multiple Models
Models change. Versions update. Capabilities shift. Content may originate from or be reviewed by different systems such as ChatGPT, Claude, Gemini, Perplexity, and Grok over the course of a workflow.
Consistency survives because it does not live inside any individual model. It lives in the system that governs how models are used.
That distinction allows orchestration to scale without erosion. Outputs feel unified not because models agree with each other, but because they are not allowed to disagree on what matters.
Why Orchestration Improves AI Visibility And GEO Outcomes
Most visibility losses in AI search do not happen because the content is weak. They happen because content is hard to interpret at machine speed. Orchestration improves AI visibility by removing friction from how meaning travels through AI systems.
Instead of repeating earlier arguments, it helps to look at what AI systems actually do with content once it is published.

How AI Engines Process Content
Before surfacing an answer, AI engines typically:
- Identify the topic and intent
- Extract entities and relationships
- Compress multiple sources into a single response
- Decide which sources are safe to reuse or cite
Orchestrated content is designed to survive this process without distortion.
Where Orchestration Changes The Outcome
Rather than improving writing quality, orchestration improves content survivability.
Interpretability becomes structural
Meaning is carried by headings, section logic, and explicit relationships, not by stylistic inference. This makes content easier to classify and reuse.
Ambiguity is reduced upstream
Unclear phrasing and overlapping ideas are resolved before the content reaches generation. AI systems encounter fewer interpretive choices, which reduces summarisation errors.
Consistency builds citation confidence
When similar questions lead to similarly structured answers across a site, AI systems develop confidence in the source. This increases the likelihood of repeated mentions and citations over time.
Why This Matters For GEO
Generative Engine Optimization rewards sources that are:
- Easy to summarise without losing meaning
- Consistent across topics and formats
- Structurally reliable under compression
Orchestration aligns content to these conditions by design, not by post-hoc optimisation. AI visibility improves not because content is optimised harder, but because it is easier for AI systems to trust.
What Users Control Vs What Addlly AI Automates
Multi-LLM orchestration works best when human judgment and system execution are clearly separated. The goal is not to remove control from users, but to focus it where it matters most.
This section clarifies which decisions remain human-led and which are handled automatically by the orchestration layer.

Strategic Inputs Users Define
Users control intent, direction, and priorities. These inputs shape outcomes without requiring technical intervention.
- Business goals, campaign objectives, and success criteria
- Target audience, market context, and competitive focus
- Brand voice guidelines and positioning boundaries
- Content scope, formats, and distribution intent
These inputs are stable and strategic. They benefit from human context, judgment, and domain knowledge.
Decisions Handled By The Orchestration Layer
Executional complexity is handled by the system, not the user.
- Interpreting inputs into structured tasks
- Routing tasks to the appropriate models
- Applying constraints for structure, entities, and clarity
- Validating outputs before final assembly
This separation prevents users from managing low-level AI behaviour while still retaining meaningful control over outcomes.
The result is a workflow where humans decide what should be achieved, and orchestration decides how it is executed reliably.
Global Language And Geolocation Support In Addlly AI
Multi-LLM orchestration also governs how content adapts across regions and languages. This ensures outputs remain contextually accurate, culturally aligned, and consistent as workflows scale globally.
Geolocation-Aware Content Execution
Users can define target geographies at the workflow level, allowing content to reflect regional context across every stage of execution.
- Aligns tone and framing with local market expectations
- Accounts for regional regulations and cultural nuance
- Adapts examples and references based on geography
Geolocation rules are enforced centrally, ensuring all models involved follow the same regional constraints.
Language Management Across Orchestrated Workflows
Apart from English, language selection is handled at the system level rather than through individual prompts. This allows workflows to support a wide range of European languages alongside an extensive set of Asian languages without introducing inconsistency.
- Language rules apply uniformly across all models
- Prevents mixed-language or unintended language drift
- Ensures outputs remain aligned across regions and markets
By managing language and locale centrally, orchestration maintains clarity and consistency even as models, workflows, and markets evolve.
Why This Works For Global AI Visibility
Search and generative AI systems interpret language and geography as signals of relevance and trust. System-level control over these factors ensures content remains legible, reusable, and accurate for both human audiences and AI engines across regions.
How Multi-LLM Orchestration Fits Into Addlly AI’s AI Visibility Stack
Multi-LLM orchestration is not a standalone capability. It sits between diagnosis and execution, connecting how visibility is measured with how content is produced and structured.
Instead of explaining this in stages again, it helps to see orchestration as a bridge inside the AI visibility stack.
Where Orchestration Sits
Think of the stack as three interacting layers:
1. Visibility Diagnosis
This layer identifies how AI systems currently interpret a brand.
- Surfaced through the GEO Audit
- Highlights gaps in entity clarity, structure, and authority
- Reveals why content is excluded or misrepresented
2. Orchestration Layer
This is where diagnosis becomes action.
- Translates audit signals into system-level rules
- Decides how tasks should be routed and constrained
- Ensures fixes are applied consistently, not manually
3. Structured Content Systems
This layer produces outputs designed for AI interpretation.
- Content is generated within defined structures
- Entity usage and hierarchy are enforced
- Outputs align with AI summarisation and citation behaviour
Relationship With GEO Audit
The GEO Audit does not exist to generate recommendations alone.
Its insights inform orchestration decisions by:
- Defining which signals need reinforcement
- Identifying structural weaknesses to correct
- Guiding how content should be framed for AI engines
Without orchestration, audits remain advisory. With orchestration, they become operational.
Relationship With Structured Content Systems
Structured content systems ensure that intent survives scale.
Orchestration ensures those systems behave consistently by:
- Applying the same visibility logic across agents
- Preventing drift between strategy and execution
- Maintaining alignment as content volume grows
Together, these layers form a closed loop: diagnose, systematise, execute, and reinforce. Multi-LLM orchestration is what keeps that loop intact.
Summary
Multi-LLM orchestration is the foundation that allows AI-driven marketing and content systems to operate reliably at scale. Instead of relying on a single model or increasingly complex prompts, orchestration breaks work into clear stages, assigns responsibility deliberately, and enforces consistency through system design.
Inside Addlly AI, this approach ensures that:
- AI outputs remain predictable, auditable, and repeatable
- Content is structured for both human understanding and AI interpretation
- GEO and AI visibility outcomes improve through clarity, not volume
- Strategic intent stays human-led while execution is system-managed
Orchestration shifts AI from being a creative assistant to being infrastructure. Models can change. Capabilities can evolve. Visibility logic, structure, and control remain stable.
For teams navigating AI-driven search, summaries, and citations, this distinction is what separates experimentation from long-term visibility performance.