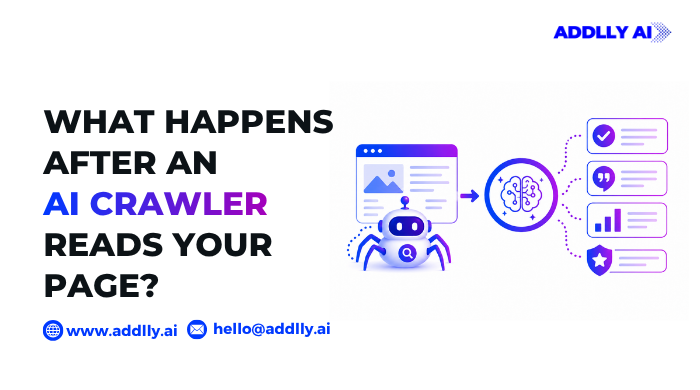
What happens after an AI crawler reads your page is the part most brands never see. The crawl is just the start. Once an AI crawler grabs your content, it parses, processes, indexes, and decides whether your page is worth citing in an AI answer. That final step shapes your visibility in tools like ChatGPT, Perplexity, and Google AI Overviews.
This guide walks through the full journey, step by step, so you know exactly what AI bots do with your content and how to make sure your page earns the citation.
Quick Summary: What Happens After an AI Crawler Reads Your Page
- After the crawl, AI crawlers parse, clean, and tokenize your page content.
- Your content gets indexed, deduplicated, and turned into vector embeddings for meaning.
- AI systems use the data as training data or live retrieval for answers.
- A citation decision follows, judging trust, structure, and relevance of your page.
- Blocked crawler access through robots.txt stops the whole process before it starts.
- Structured data and clear markup help AI bots cite your page faster.
What Does It Mean When an AI Crawler Reads Your Page?
When an AI crawler reads your page, it pulls your content into a pipeline that powers AI answers. AI crawling is the process by which AI systems discover and collect content from the web, so they can include it in AI-generated answers. Unlike a human reader, AI bots don’t see your design. They read the raw text, links, and structure your server sends back. The goal is simple: gather clean, usable content for AI models.
So the crawl is only the doorway. The real work, parsing, indexing, and the citation decision, happens after AI bots crawl your page and start processing the website content they found.
What Are the Main AI Crawlers and User Agents Reading Your Page?
Several AI crawlers visit websites every day, each with its own user agent. A user agent is the name a bot uses to identify itself in your logs. Knowing these AI user agents tells you which AI platforms are reading your content.
The main ones include:
- GPTBot, which feeds ChatGPT.
- ClaudeBot, used by Claude.
- PerplexityBot, used by Perplexity.
- Google Extended, which controls how Google uses your content for AI.
These AI bots crawl your pages using clear user agent strings. If you spot them in your logs, your content is reaching AI tools. If you never see them, something is blocking crawler access.
What Happens After an AI Crawler Reads Your Content: The Full Process
Step 1 – The Request and the Server Response
It starts with a simple request. When an AI crawler visits a website, it sends an HTTP request to the server, which responds with the website’s HTML code, allowing the crawler to parse and process the content. That HTML structure carries everything: your text, headings, links, and meta descriptions. The crawler reads this raw code, not the polished page a human users see in a browser.
If your server is slow, weak page speed can cut the crawl short. Fast, clean responses help AI bots grab your full content. This first exchange sets up every step that follows.
Step 2 – Parsing and Text Normalization
Next comes cleanup. The raw HTML is full of code, so AI bots strip it down to the words that matter. Text normalization involves converting text to lowercase and removing punctuation. Then tokenization breaks sentences into individual words or sub-words, called tokens. Natural Language Processing (NLP) tags parts of speech and entities in the text.
At this stage, AI determines the tone and emotional context of the content. The system reads not just what you wrote, but what it means. Clean, well structured content makes this easy. Messy pages full of scripts slow AI crawlers down and risk losing your key points.
Step 3 – Indexing, Deduplication, and Canonicals
Now the content gets organized. Search engines create inverted indexes that map text to URLs for fast information retrieval. This search index is how AI engines find your page later without reading the entire web again. Before that, search engines perform deduplication to identify canonical versions of web pages. If three URLs hold the same content, only one canonical page makes it into Google’s index. This stops duplicate clutter.
Good page structure helps here. Clear URLs and tidy code let AI bots crawl and store your important pages efficiently. Sloppy duplicates waste crawl budget and can bury the version you actually want cited.
Step 4 – Vector Embeddings and Semantic Understanding
Here the content becomes math. AI transforms indexed content into vector embeddings to understand contextual meaning and topic relationships. Machine learning models convert text into mathematical vectors, called embeddings. Why does this matter? The search engine moves from exact keyword matching to semantic understanding of content. So AI systems grasp meaning, not just words. A page about crawl rates connects to crawler access even without the exact phrase.
This is also how AI-driven search engines support Retrieval-Augmented Generation (RAG) pipelines by structuring web data into machine-readable formats. Strong, clear content gives these AI models a sharper signal to work with. Better signals lead to more accurate AI responses.
Step 5 – Training Data or Real-Time Retrieval (RAG)
After processing, your content takes one of two paths. Some AI crawlers collect pages as training data, used to teach AI models during training. AI crawlers scan web pages and the data undergoes processing, indexing, and model training, changing how search engines retrieve information. The second path is live. Many AI bots fetch content in real time when a user asks a question. Some AI agents go further and complete tasks on the user’s behalf. This retrieval feeds RAG, where the model pulls fresh facts instead of relying only on pre trained knowledge.
Both paths matter. Training models shape what AI knows broadly, while real-time retrieval decides which page answers a specific user request right now.
Step 6 – The Citation Decision
This is the moment that counts. Before naming your page in AI answers, AI systems assess experience, expertise, authoritativeness, and trustworthiness (E-E-A-T) of web pages. Search engines evaluate how well content answers specific user queries rather than just counting keyword density. So a clear, direct answer beats a keyword-stuffed page every time. The system also compares your content against its index using algorithms and ranking signals to determine the best answer.
If your page wins, it earns a citation inside the AI generated answers people read in chat interfaces. If it loses, a competitor gets named instead. This single decision shapes your whole AI visibility.
What Happens If AI Crawlers Can’t Access or Read Your Page?
If AI crawlers can’t reach your page, none of this happens. Your content stays invisible to AI search. AI crawlers can only access content that is publicly available and not blocked by robots.txt or noindex tags. Setting up these files the right way keeps you visible. Many site owners block AI crawlers by accident. A strict robots.txt or a stray noindex tag can shut out every automated bot at once. Heavy scripts cause trouble too. If key text loads only through code that bots skip, they read an empty page. Check your txt file, review your bot management rules, and don’t restrict access to the pages you want cited.
How Do AI Crawlers Differ From Traditional Web Crawlers?
AI crawlers and traditional web crawlers do related jobs, but with different goals. Traditional SEO focuses on ranking websites in search results, while AI crawling emphasizes how AI systems discover and utilize content for generating answers. AI crawling is more selective than traditional SEO crawling. It retrieves specific content to answer user queries rather than indexing entire websites for ranking. So modern crawlers act more like researchers than librarians. Some are AI agents that fetch pages the moment a user needs an answer.
Here’s the core difference:
| Traditional Crawlers | AI Crawlers |
|---|---|
| Goal: index pages for ranking | Goal: retrieve content for answers |
| Reads the whole site | Pulls only what answers a query |
| Powers traditional search engines | Powers AI chatbots and AI search |
| Success = search rankings | Success = citations in AI answers |
Both still matter. Traditional crawlers feed search results, while AI bots feed AI answers. Smart brands optimize for both at once.
What Signals Decide If Your Page Gets Cited?
1. Clear Page Structure and Heading Hierarchy
Structure is the first thing AI bots check. AI search engines prioritize clear, structured content with proper heading hierarchy, which helps them understand organization and importance. A clean heading structure acts like a map. Your H1 names the topic, H2s split it into sections, and H3s handle the details. When headings match real questions, AI systems find answers fast.
Using clear, descriptive headings and structured data allows AI systems to better parse and reference content. Short paragraphs help too. Add alt text to images so bots know what each picture shows. Clean meta descriptions and clear alt text give bots extra context. Clear page structure turns a wall of text into citable answer blocks.
2. Structured Data and Schema Markup
Structured data is your fast track to being understood. To optimize for AI, websites should implement structured data, which helps AI crawlers understand the content’s meaning and context more effectively. Schema markup is the code that does this. Structured data, such as schema markup, helps AI crawlers understand the meaning of your content quickly, making it easier to extract accurate information for responses. It works like a label on every part of your page.
Implementing structured data can improve how often AI bots crawl your pages and how well they understand them, acting as a cheat-sheet for the content. FAQ, How-To, and Article schema are strong picks for most pages.
3. Freshness and Maintenance Signals
AI favors content that looks maintained. Keeping content updated with publication dates and recent information signals to AI that the website is actively maintained, which can improve visibility in AI-generated responses. A visible publish or update date tells AI crawlers your facts are current. Stale pages with no dates look risky to cite, so AI may pick a fresher source instead.
Update key pages on a schedule. Refresh stats, fix old links, and add new sections when topics change. Keeping pages up to date is a simple habit that protects your spot in AI answers. Fresh, active content earns more trust from every AI engine over time.
How AI Crawler Activity Affects Your Website Traffic and Visibility?
AI crawler visits show up in your data before they show up in your sales. In your logs, bot traffic from AI crawlers can climb fast, even while clicks stay flat. On busy pages, this bot traffic can rival your human visitors. That’s because AI search tools often provide direct answers to user queries, which can lead to a decrease in traditional website traffic if businesses do not optimize for AI visibility. Users get the answer in chat and never click.
So crawler traffic can rise while human visitors fall. The win is no longer only a click. It’s the mention. Strong AI crawler traffic plus citations builds brand visibility inside AI answers, which protects you as habits shift.
Why AI Visibility Now Matters as Much as Traditional SEO?
AI visibility now matters as much as traditional SEO for brand awareness, as users increasingly rely on AI generated answers for information. AI now powers a large share of web searches, and more users open AI search tools before classic search engines.
The rise of AI-driven search means that businesses must adapt their content strategies to ensure visibility in AI-generated responses, which can directly impact traffic and brand recognition.
Traditional SEO still builds the base. Clean crawler access and quality content help AI bots find you. But ranking alone no longer guarantees a mention.
Today, AI driven search can answer a question without sending a single visitor. If you’re not in Google’s AI Overviews, a competitor is. Traditional search engines still matter, but they’re no longer the only path. That’s why digital visibility now lives in two places: search results and AI search.
How to Make Sure Your Page Gets Processed and Cited?
1. Confirm Crawler Access and Check Your Server Logs
First, prove the door is open. Open your robots.txt and confirm crawler access for the main AI user agents like GPTBot, ClaudeBot, and PerplexityBot.
Next, read your logs. They show which AI bots visited, how often, and which pages they fetched. Rising bot traffic is a healthy sign; if you see no crawler traffic, something is blocking them.
Also watch google crawlers and Google Extended, since they shape how Google uses your content. A quick log check each month catches access problems early. Clean crawler access is the base every other fix sits on, so confirm it before you touch your content.
2. Structure Content for Easy Extraction
Next, make your content easy to lift. Lead each section with a direct answer, then explain. When a user asks a question, your first sentence should answer it plainly.
Use question-style headings that match real searches. Keep paragraphs to two or three sentences. Add lists and tables, since AI bots pull these almost word for word.
Add schema markup so each part is labeled clearly. Use plain, descriptive language for your website content and skip jargon that confuses web crawlers. Well structured content like this lets AI crawlers grab a clean answer with zero extra work, which makes your page the easy choice to cite in AI search.
3. Keep Content Fresh and Up to Date
Finally, treat content as living, not done. Add a clear publish and update date to every key page so AI crawlers can see how current it is.
Review your top pages on a set schedule. Refresh numbers, swap dated examples, and add fresh sections as topics shift. This keeps your facts accurate for AI summaries.
Fast pages help too. Good page speed lets bots read more of your content in each visit. Together, fresh facts and quick loading keep your important pages ready for every crawl. Staying up to date is the easiest way to hold your place in AI search over time.
How Addlly AI Helps You Get Cited Across Every AI Engine?
Knowing what happens after the crawl is one thing. Winning citations at scale is another. That’s where Addlly AI comes in. Addlly AI is an AI Search Visibility platform that tracks how AI engines show your brand across ChatGPT, Gemini, Perplexity, Claude, and Google’s AI Overviews. Instead of guessing why AI crawlers skip your pages, you get a clear picture and a clear fix.
The platform runs citation forensics to show which sources AI pulls from, automates schema markup, and builds AI-optimized content that AI tools cite across every engine.
Want to see where you stand? Run Your GEO Audit with Addlly AI today. No signup or credit card needed.
Frequently Asked Questions About What Happens After an AI Crawler Reads Your Page
Do AI Crawlers Store My Page or Just Read It?
It depends on the bot. Some AI crawlers only read your page in real time to answer a question, then move on. Others collect and store your content as training data for AI models. Either way, clean, accessible content gives you the best shot at a citation.
Can I See AI Crawler Activity in My Server Logs?
Yes. Your server logs record every visit, including AI bots like GPTBot and PerplexityBot. Look for their user agent strings to spot AI crawling. If you track this often, you can confirm which AI platforms reach your content and catch any access issues fast.
Should I Block AI Crawlers From My Site?
Usually not. If you block AI crawlers, your content can’t appear in AI answers, which cuts your AI visibility. Most brands should allow the main AI bots and only restrict access to private or paid pages. Open crawler access is what lets AI find and cite you.
Does Structured Data Really Help AI Cite My Page?
Yes. Structured data acts like a cheat-sheet for AI bots. This markup labels your content so AI systems understand it without reading every word. This makes your facts faster to trust, extract, and cite. Pages with clear markup are easier for AI tools to use in answers.
How Is AI Crawling Different From Traditional Search Indexing?
Traditional SEO focuses on ranking websites in search results, while AI crawling emphasizes how AI systems discover and utilize content for generating answers. Traditional search crawlers index an entire site for ranking. AI crawling is more selective and pulls specific content to answer a query, not to build a search index.
How Long After a Crawl Does My Page Appear in AI Answers?
It varies. For tools that use live retrieval, your page can show up in AI answers within hours of a crawl. For training data, it may take a full model update, which can be months. Fast, clean crawler access and fresh content speed things up across most AI tools.

